-
 数据获取
数据获取
背调后台管理的一篇技术贴,来自Checkr的工程师,背调的童鞋可以仔细看看
构建软件来管理背景调查的复杂性
在Checkr,我们正在构建软件以帮助公司大规模招聘,我们的背景调查是实现这一目标的重要组成部分。
从表面上看,背景检查看起来很简单 - 您可能认为它就像在数据库中查找记录并返回一些数据一样简单,但实际上它很麻烦而且很慢。
在非常高的层面上,背景调查分为两个阶段:
获取数据 Getting Data
报告数据 Reporting Data
这篇博客文章的目的是帮助揭示Checkr如何构建软件来管理这种复杂性,并帮助我们的客户和寻找工作的人员进行背景调查的现代化。
获取数据
获取数据可能看起来很简单。一对API调用,解析一些JSON,一些for循环,我们进行了后台检查。而在一个非常高的水平你是对的,但是,它远远不是那个干净或简单。
有一些国家数据库可以随意汇总州和县报告机构的记录。它们包括XML文档,其中包含标记,这些标记本身包含base64编码的XML文档🤯。如何描述这些数据没有标准 - 我们必须将其标准化为我们的系统,客户和申请人可以理解的东西。
“Nolle Prosequi”?是的......对于“案件被驳回”而言,这实际上是拉丁语,现在仍在现代法庭中使用!并且,有时(通常)拼写错误!
有54个DMV(是54!不要忘记波多黎各,关岛,美属萨摩亚和华盛顿特区),它们都以不同的方式处理记录。有100个市镇和州数据库。美国大约有大约3,000个县,它们都有独特的法律和法规来管理我们如何报告数据。
让我们关注各县,因为它们代表了我们最大的数据表面区域。我们可以把县分为两组 - 有电子记录的县(快👏)和有实物记录的县(慢😨)。
SELECT court_access_method,SUM(population)
FROM
COUNIES GROUP BY court_access_method;
>>
court_access_method population
electronic_records_available 160,259,716
in_court_researcher 87,369,080
clerk_assisted_county 61,125,939
以上是我们专有的内部数据库之一的查询,用于管理各个县的元数据。它基于各种来源,包括人口普查数据,投票记录,邮政数据和各种政府名单。它告诉我们,目前 48%的美国人口居住在缺乏电子记录的县。(我在看加州...😅)
缺乏电子记录意味着我们需要亲自送人进入法院,排队等候,与法院书记员交谈,进入地下室,打开档案柜,拉出一张实物纸,避免剪纸,阅读记录,将它们输入手机,最后将记录提交给我们。
让我们说一个给定的申请人我们搜索5个县,其中3个离线。我们的系统会将每个县的工作分成长期的异步工作:
有些可能会在几秒钟内完成,有些可能是几天,如果他们离线。
如果我们的质量标准不符合,有些人可能会尝试使用在线资源并回退到离线资源。
有些可能导致指针或转移案件,这意味着我们需要在其他地方开始另一个县搜索。
我们使用Kafka来管理这些异步任务,以便不同的服务和团队可以可靠地实现每种搜索类型。我们正在研究更明确的工作流框架,工具和可视化,以帮助管理生产中的这些工作。
一旦所有工作完成并且我们有最终的结果列表,我们就开始下一阶段......
报告数据
联邦,州和郡法律影响背景调查的运作方式,不同的政府机构负责执行这些法律。他们通常这样做是出于很好的理由 - 保护消费者。仅仅因为某人多年前犯了错误并不总是意味着这会对他们的工作机会产生负面影响。为此,我们需要分析每个结果以确保它符合要求。我们的软件负责帮助保护消费者并遵守这些法律。
甚至有些法律会影响某些类型的雇主如何使用背景调查中发现的结果。例如,法律通常要求医生,护士,财务顾问,家庭护理提供者和运输公司取消具有某些犯罪的个人的资格。而且,这些法律甚至可以相互矛盾!
因此,Checkr需要一个系统来应用这些规则并正确地确定我们能够和不能报告哪些数据。
这是一个示例规则:
if(record.arrest?|| record.dismissed?||
record.alternative_adjudication?)&&
record.date <= 7.years.ago
record.display = false record.save
!
结束
这描述了我们应该如何处理7年前被解雇的记录。record.display = false - 我们不应该报告它们。
这种类型的系统运作良好,但多年来一直存在一些成长的痛苦。
在上面的示例中,规则仅存在于代码中。非工程师无法剖析这一结果并了解发生的情况和原因。如果我们质量团队的某人正在调查记录,我们将无法为他们提供上下文。“这个记录为什么隐藏?”他们可能会问。我们可以像这样扩展它:
record.display = false
record.reason =“隐藏逮捕/解雇/ alt超过7岁”record.save
!
这是一种改进,我们至少有一些原因与现在的结果有关。但是,它仍然与记录模型紧密结合。
有副作用,因为它更新记录上的数据。
合规逻辑是硬编码的(工程师不是专家),因此在我们的法律团队(他们是专家)无法访问的地方。
对当前时间有一种微妙的依赖(如果我们想在以后重新运行这个规则怎么办?或预测6个月后的结果会是什么?)。
我们怎么解决这个问题?
规则引擎
规则引擎提供简单的合同,允许我们拆分规则,数据,结果和代码。
results = engine(规则,数据)
这是与JSON相同的规则,用于输入规则引擎:
{
“event”:{
“params”:{
“display”:false,
“message”:
“隐藏/解雇/替代7岁以上”,
}
},
“条件”:{
“all”:[
{
“fact”:“applied_filter”,
“operator”:“in”
“value”:[
“arrest_filter”,
“ dismissed_filter ”,
“alternative_adjudication_filter”
]
},
{
“fact”:“years_since_context_date“,
”operator“:”greaterThanInclusive“
”value“:7
}
]
}
}
为什么规则用JSON表示?
如果你有非常复杂的规则(例如,基于候选人的地理位置,帐户设置,其他规则的存在等),那么if / else语句变得难以管理。
我们现在可以在UI或PDF中呈现这些规则,我们可以以他们能够理解的方式为我们的法律团队和监管机构提供。
我们可以对规则进行快照并针对相同的数据运行多个规则集。例如:当我们进行更改时,我们可能希望针对以前的生产结果运行更改并比较差异(我们在内部称之为回测)。
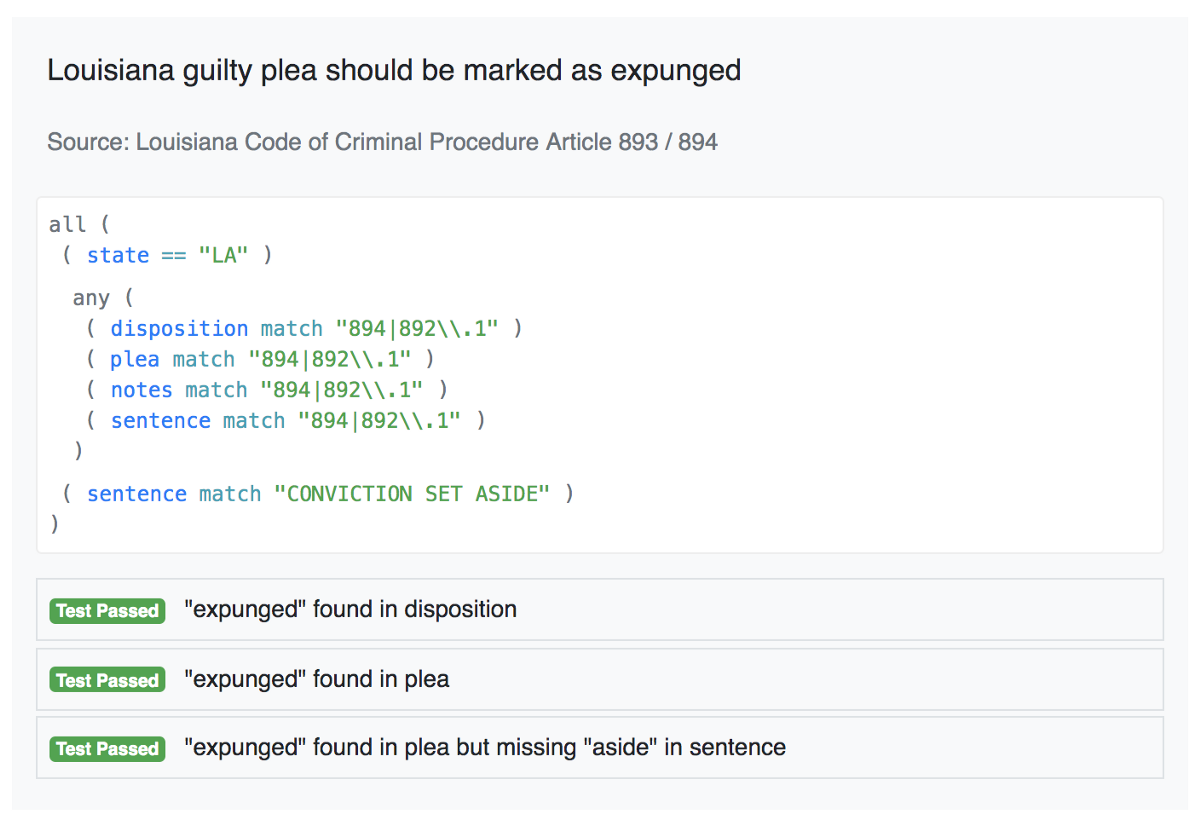
以下是为我们的法律团队提供的规则:
这是一个更复杂的规则,具有自定义UI和测试工具:
具有WIP UI /测试工具的复杂规则
以上是概念证明,但代表了我们的方向 - 我们还有很长的路要走。但是,最终它将允许我们在法律变化时更快,更自信地行动,因为我们可以轻松地测试和重现结果。
后台检查过程中的每一步都是混乱的,容易出错,难以推理,对于求职者来说很可怕,并且受到一长串不同实体的控制。在Checkr,我们的目标是让这个过程对我们的申请人公平 - 并且从简单直观的界面开始,解决这个复杂的问题。
如果这听起来很有趣,我们正在招聘!还有很多问题需要解决!
以上由AI翻译完成,HRTechChina旨在帮助传递信息,扩大视野~
原文来自:Checkr Ben Jacobson
 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina